Eloqua内で自動的にデータクレンジングを実行させる
マーケティングオートメーション活用とデータクレンジングは密接に関わります。今回はEloquaで自動的にデータクレンジングを行う仕組みを実装することを考えてみます。
参考:Eloqua導入前に知っておくべき10のポイント
なぜマーケティングオートメーションにデータクレンジングが必要とされるのか
データクレンジングはマーケティングオートメーションに限らず、様々な顧客データを扱うシステムに求められる作業です。しかし、マーケティングオートメーションにおいては特にデータクレンジングが重要となる理由がいくつかあります。
まず、Webサイトのフォーム経由でのデータ流入が多い、というのがその1つです。
CRMでは、基本的に営業マンが名刺交換した潜在顧客のデータが格納されるケースが多いでしょう。名刺スキャンシステム・サービスなどと組み合わせてデータインポートを行うことで、かなりの精度で「正しいデータだけをインポートする」ことが可能になりそうです。(もちろん、各営業マンが個々に手打ちしているケースも多いのでその場合はデータがすぐに汚くなってしまうことは想像に難くありません。)
しかし、Webフォーム経由でデータが入ってくる場合、データの入力者は潜在顧客であり、正式なものかどうかは入力者次第です。
もちろん、Webフォームのバリデーション(フォームへの入力規則)によってある程度は防げるかもしれません。例えば、法人形態(株式会社か有限会社か合同会社か)を選択させ、前株か後株かを選ばせる、などの入力方法を採用することである程度綺麗なデータを格納できます。しかし、これをマーケティングオートメーションの仕組みと連動させることは手間ですし、ユーザービリティやコンバージョン率への影響も気になるでしょう。
2つ目に、マーケティングオートメーションツールには「様々なデータのインポート元がある」、ということもデータクレンジングが重要となる理由です。
協賛イベント参加者リスト、自社セミナーへの参加者リスト、CRMからのデータインポートなど様々な形式の顧客データが、マーケティングオートメーションツールに統合されます。Excelなどで加工してからインポートすれば良いのですが、個人情報をExcelで加工することのリスクや、加工ルールの統一などは厄介な問題です。
こうしてマーケティングオートメーション内のデータは、様々な形式の顧客データが混在したものとなっていきます。
データクレンジングにもいろいろある
「データクレンジング」と言っても様々な意味合いで使われることが多いようです。最もイメージしやすいデータクレンジングは、表記を正しいものに修正し、重複しているデータを統合するようなものかもしれません。
しかし会社名などの表記にゆらぎがある場合に正しいものに修正する、というのは実は機械的に行おうとすると非常に厄介なものです。
例えば、「株式会社アンダーワークス」「アンダーワークス株式会社」という2種類のデータが存在しているときに、どちらが正しい社名なのか、ということを判断することは簡単にはできません。
まず、同名で前株・後株違いの別社名ではないのか(つまり両者とも正しい社名)、どちらかが間違っている場合はどちらが正しいのか(つまり是となる社名リストを参照する必要がある)などは、目視で一件一件確認しないとクレンジングできないものでしょう。
一方で「一定のロジックで異なるデータ形式を綺麗なものにする」というクレンジングは機械的に行うことが可能なクレンジングです。
例えば、「(株)」と表記されているものを「株式会社」に置換するといったものです。また、(03)と03-から始まる電話番号をどちらかに統一する、といったものも同様です。
こうした異なるデータ形式の修正・統一は、Eloqua内にロジックを作り自動化することで綺麗なデータを常に保つことが可能です。
Eloquaの新機能「プログラム」に実装された「Contact Washing Machine」
Eloquaには、もともと「プログラムビルダー」と呼ばれるデータ管理ツールが実装されており、「更新ツール」と組み合わせることで、データクレンジングを実装できました。ただこの「プログラムビルダー」は、実装が複雑(つまり難しい)であり、実行にも時間がかかる(5分バッチの優先モードは3つまでしか実装できないなど)という難点もありました。
今回は、新しく実装された「プログラム」内のデータクレンジング専用機能の「Contact Washing Machine」を利用しますが、これは、ほぼリアルタイムで実行され、設定難易度もそんなに高くないため、Eloquaでのデータクレンジング自動化のハードルが一気に下がったと言えます。

この「Contact Washing Machine」では、「特定の列に格納されているデータをある条件に合致した場合に、特定のロジックで修正し、特定の列に上書きする」ということが可能になります。
そして、条件や修正・置換のロジックを正規表現も含めフレキシブルに定めることができるため、データクレンジングのロジックを作っておけばその通りに勝手にデータを綺麗に修正し続けてくれます。
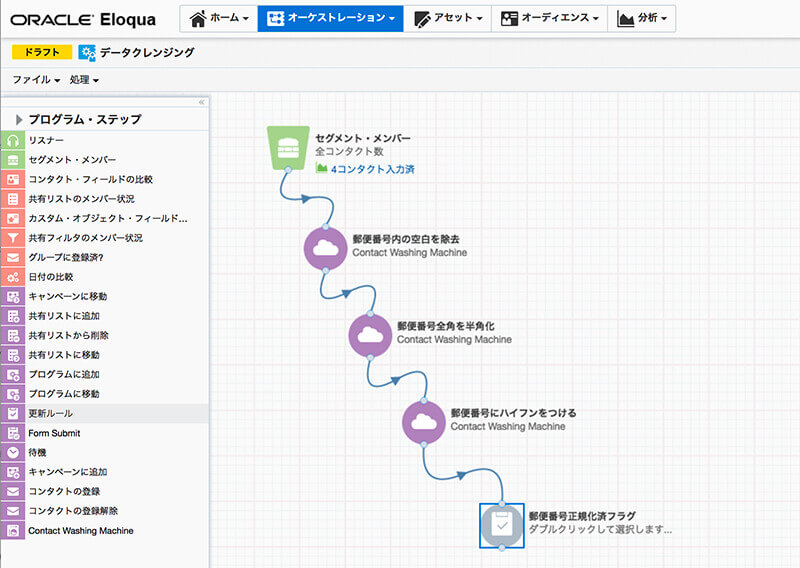
Contact Washing Machineの実際:ハイフンの入っていない郵便番号を見つけて、3桁ハイフン4桁に修正する
試しに、簡単なデータクレンジングのプログラムを組んでみます。
郵便番号などは常に同じ形式でデータが入ってくるはずだ、と思われる方も多いかもしれません。しかし、実際にマーケティングオートメーションツール内を見てみると、意外にもハイフンありとハイフンなしが混在する状況が起っていることがよくあります。
そこで、郵便番号のデータ列に、「ハイフンなしの郵便番号」があった場合に、「3桁ハイフン4桁」と修正するプログラムを作り、これをデイリーバッチ(毎日1回実行)するプログラムを組んでみます。
この場合、「プログラム」に対して、郵便番号のデータがハイフンなしの7桁で格納されているデータを検索して追加し、それらを3桁と4桁にグループ化し、間にハイフンを挟んでデータを上書きする、という設定を行います。
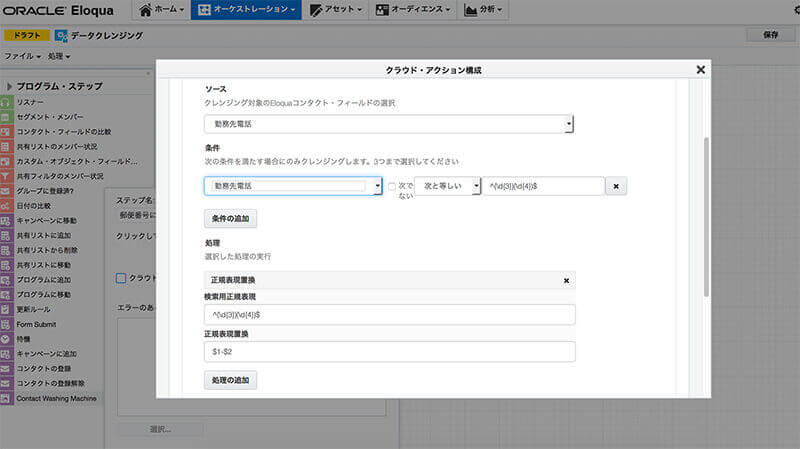
「Contact Washing Machine」では、データの検索や置換に正規表現も使えるため、ある程度複雑なデータの置換が可能になります。今回は、
「勤務先電話番号」のデータを ^(d{3})(d{4})$ という正規表現で検索し、$1-$2 という形で上書きする、という設定にしました。これで、Eloquaが毎日自動的にハイフンなしの郵便番号をハイフンありに統一してくれます。
「Contact Washing Machine」を利用して他にもできるデータクレンジング
他にもデータ形式の統一などでは以下のようなものが実装できると思います。
・全角の電話番号・郵便番号を半角に修正
・空白・スペースの除去
・(株)、(有)を株式会社、有限会社に置き換え
・(03)から始まる電話番号を03-などに統一
・090、080、070など電話番号が携帯だったときに別の列に格納
・ 全角を含む住所を半角に統一
・住所の都道府県と市町村を抜き出して別の列に格納
このようなデータ形式の統一はある程度簡単なロジックで実現可能である一方、これらを目見で行うのは意外と大変ですから、ツールに自動実行させるにはうってつけです。
部門や役職の分類化までできれば、セグメントの精度向上に大きく貢献
難易度は高くなりますが、「役職」や「部門」などのデータを分類するところまでプログラム化できれば、実はセグメントの精度向上に大きく貢献します。
例えば、役員以上のリードだけにあるキャンペーンメールを打ちたいという時があると思います。一方で、役員といっても役職は様々です。「代表取締役」「専務取締役」「常務」「執行役員」など。外資系も含めると「Executive Vice President」「CEO, President」といった役職もあります。
こうした様々な役職をリスト化しておき「役職クラス」という別の列を用意しておきます。上記のような役職が含まれている場合には、「役員クラス」というデータが自動的に書き込まれます。これで、(精度は100%ではないですが)役員だけをセグメントすることが非常に容易になります。
Eloquaを活用されている企業でデータクレンジングに悩んでいらっしゃる場合には、是非このContact Washing Machineを使ってみることをおすすめします。